Recuperacion de desastres en ambientes virtuales VMware – escenarios y conceptos generales

Estaba escribiendo un post sobre Disaster Recovery as a Service (DRaaS) basado en VMware Site Recovery Manager cuando me di cuenta de que venía para largo el tema y más que un nuevo post se perfilaba como un capítulo para un libro en la materia. Teniendo en cuenta que en un post demasiado extenso el lector tiende a perderse o incluso perder el interés en el mismo decidí escribir este nuevo post en el blog de Wetcom concentrándonos únicamente en los conceptos básicos y en ambientes virtuales sin hundirnos en la complejidad que la materia de recuperación de desastres y continuidad de negocios requiere.
Primero que nada tenemos que entender los puntos básicos de tiempo sobre los cuales se trabaja en un plan de recuperación de desastres que son el RPO (Recovery Point Objective) y el RTO (Recovery Time Objective). Estos dos valores de tiempo son los que definen básicamente lo siguiente:
-
RPO: El Recovery Point Objective es el punto en el tiempo desde el cual recuperamos nuestra información. En otras palabras es la cantidad de información que podemos tolerar perder medido en tiempo desde el último respaldo disponible o bien desde el último trabajo de replicación exitoso. A mayor RPO mayor es la pérdida de información.
-
RTO: El Recovery Time Objective es el tiempo en el que volvemos a poner nuestros servicios en funcionamiento para dar servicios a nuestros usuarios o bien a nuestros clientes. A mayor RTO mayor es el tiempo que demoramos en volver a brindar servicios.
Desde un punto de vista más gráfico podemos verlo de esta forma:

Los cálculos de RTO y RPO no deben ser tomados a la ligera y para determinar los mismos se debe involucrar a toda la organización en un relevamiento de requerimientos de negocio el cual entregará los valores correctos. Este estudio o relevamiento está completamente fuera del alcance de este post.
Una vez definidos los valores de RTO y RPO tenemos que trabajar en los diferentes escenarios básicos de recuperación de desastres en ambientes virtuales:
-
Respaldo y recuperación: algo complejo en los ambientes físicos y algo bastante más simple sobre ambientes virtuales ya que cada máquina virtual es simplemente un conjunto de archivos. Esta opción es de las más económicas ya que lo único que necesitamos es una buena solución de backup y un ambiente virtual donde recuperar nuestros servidores virtuales y luego comenzar a iniciar los mismos ordenadamente.
-
Replicación bajo demanda: esta alternativa es un poco más costosa que la de respaldo y recuperación pero logra ahorrarnos tener que trabajar con soluciones de backup para la recuperación si podemos tolerar la pérdida de información desde nuestro último trabajo de replicación. Llegado el momento de recuperar nuestro ambiente ante un desastre o algún evento que nos impida trabajar en nuestro centro de cómputos debemos contar con un ambiente virtual donde recuperar nuestros servidores virtuales y luego comenzar a iniciar los mismos ordenadamente.
-
Replicación y orquestación: desde la aparición de VMware Site Recovery Manager los escenarios cambiaron un poco ya que podemos tomar los beneficios de la replicación de almacenamiento (en la versión 5 del producto esto cambia, ya vamos a hablar al respecto) y además de esto orquestar el inicio de los servicios en el sitio secundario siguiendo el plan de recuperación definido sin necesidad de "ponernos a pensar" durante la marcha en medio de la crisis.
Habiendo visto los tres escenarios anteriores podemos exponer la siguiente tabla que si bien dependiendo del momento en que ocurre el incidente y las tecnologías de replicación puede modificarse pero generalmente muestra los siguientes valores:

Tengo que destacar que en los dos primeros casos deberíamos iniciar los procesos de recuperación de forma manual y siguiendo un plan que debe estar escrito en "papel" previamente para evitarnos dolores de cabeza al momento de la ejecución en el escenario real. Este punto queda completamente automatizado si utilizamos VMware Site Recovery Manager ya que el producto se encarga de automatizar completamente el proceso de inicio en el sitio secundario.
Como conclusión tengo que aclarar que para cada caso en particular debemos analizar cual es la mejor opción de tecnología de recuperación de acuerdo a los tiempos de RTO y RPO como así también de nuestro presupuesto para nuestro plan continuidad de negocios o recuperación de desastres. Como vimos en la tabla anterior las magnitudes de RPO y RTO son diferentes de acuerdo a la tecnología que utilicemos y esto, como siempre, se traduce en la cantidad de dinero que debemos invertir en nuestra solución de DRP.
Nicolas Solop
VMware vExpert



La ruta con Flex CUDs en GCVE
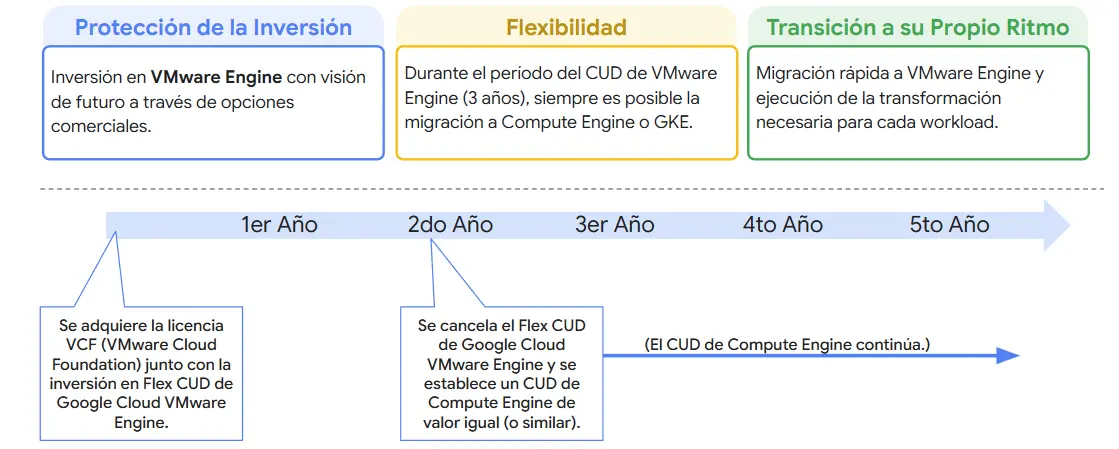
Siguiendo la captura anterior, tu inversión en los nodos de GCVE queda protegida durante todo el ciclo. Si en el segundo año decidís migrar una carga de VMware hacia Compute Engine (GCE) o GKE, podés cancelar el CUD de GCVE y transferir su valor remanente para establecer un nuevo CUD equivalente en GCE o GKE.
Esto te permite mantener el descuento, conservar el ahorro y acompañar la evolución de tus workloads, reflejando de manera precisa el enfoque de Lift, Run & Transform.
Conectividad Nativa: El Primer Paso hacia PaaS
Como mencioné antes, uno de los errores más comunes es ver GCVE como un silo. Su verdadero valor está en su conectividad nativa de baja latencia con el ecosistema de Google Cloud. Una vez que tu entorno VMware está en GCVE, tus aplicaciones heredadas están literalmente a milímetros de consumir servicios nativos de Google.
No aprovechar estos servicios nativos representa una pérdida del TCO real de la infraestructura. Por eso es fundamental utilizar el tiempo que GCVE ofrece para ser estratégicos con cada aplicación y planificar qué workloads pueden modernizarse sin disrupción.
Desde Wetcom hacemos especial foco en identificar el consumo base para dimensionar Flex CUDs con precisión, asegurando ahorro en todo el cómputo y habilitando una transición ordenada hacia otros servicios cuando tenga sentido.
Algunos ejemplos de caminos posibles y que podemos probar con PoCs sin disrupción incluyen:
- Hacia Google Compute Engine (GCE): Ideal para workloads que pueden beneficiarse de familias de máquinas especializadas, incluidas instancias con GPU o TPU.
- Hacia servicios PaaS de Bases de Datos: Como Cloud SQL, AlloyDB o Cloud Spanner. Muchas de estas transiciones se logran de manera transparente utilizando el servicio nativo Database Migration Service (DMS) para migraciones homogéneas. Esto libera la carga operativa de los DBAs delegando la responsabilidad a Google.
Un dato de valor, la posibilidad de probar bases de datos como las que mencione y sin disrupción es un gran beneficio, ya que al tener baja latencia entre GCVE y el servicio nativo, las pruebas de concepto no impactan el servicio de producción. - Hacia Contenedores (Cloud Run / GKE): GCVE facilita identificar qué VMs son candidatas naturales para avanzar hacia modelos cloud-native cuando llegue el momento.
Seguridad Nativa y Mitigación de Riesgos
Y no nos limitemos únicamente en la modernización de nuestras aplicaciones. La preocupación por la seguridad en la nube es natural, y en Google Cloud se aborda con un enfoque de “menor privilegio” y “guardrails” claros.
- La interconexión de GCVE con el VPC del cliente permite configurar micro-firewalls granulares, garantizando que solo los puertos y servicios estrictamente necesarios estén abiertos.
- Servicios como Cloud Armor, Next Generation Firewall (NGFW) y Security Command Center (SCC) ofrecen una batería de protección y análisis. SCC, en particular, analiza la infraestructura y alerta sobre riesgos, ofreciendo una guía de best practices para mitigar vulnerabilidades como ataques de ransomware.
- Y algo fundamental: establecer un Foundation adecuado desde el inicio, definiendo límites, permisos y controles por perfil de usuario, para evitar configuraciones riesgosas o costos inesperados. Desde Wetcom podemos acompañarlos en este diseño.
Pero mejor, veamos esta gráfica que resume claramente el recorrido que estamos describiendo:
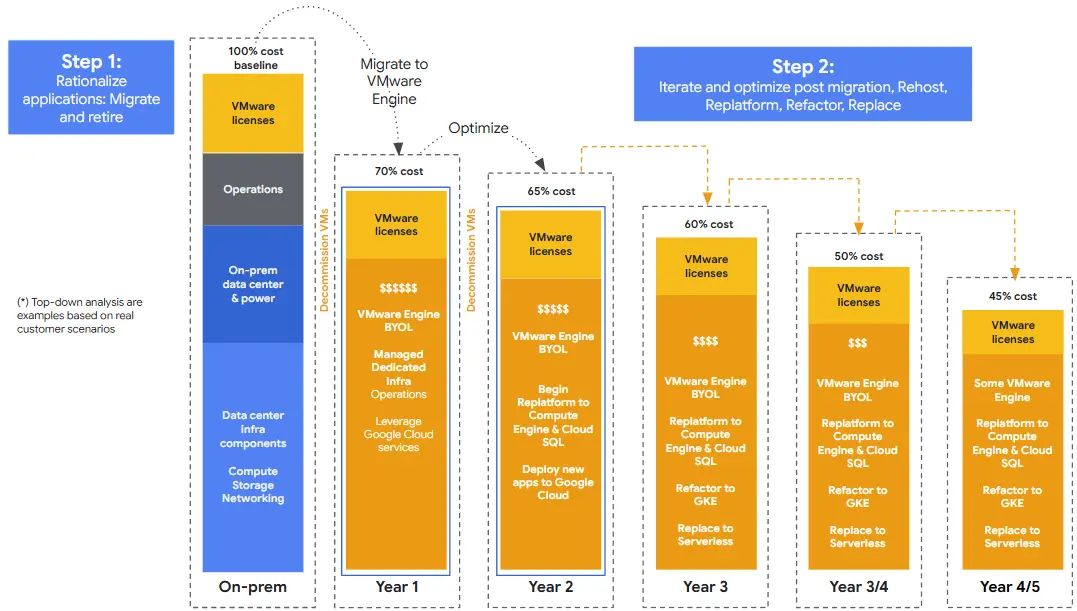
Esta gráfica de Google Cloud resume la hoja de ruta que podemos diseñar, mostrando cómo se pasa de un costo base del 100% on-premise a aproximadamente un 45% del costo original en el quinto año. Lo interesante es que este ahorro puede sostenerse —y amplificarse— gracias a los Flex CUDs, que permiten transicionar el compromiso a distintos servicios de cómputo a medida que avanzamos con el Replatform & Refactor hacia servicios como GCE o GKE. Esto habilita liberar nodos de GCVE y reducir, de forma progresiva, parte del licenciamiento de VMware que quedaría en desuso.
El resultado final es un entorno híbrido optimizado:
- GCVE para aquellas aplicaciones legacy que necesitan seguir ejecutándose allí, a milímetros de los servicios nativos de Google.
- Y el resto de las aplicaciones ya modernizadas sobre GCE, GKE o bases de datos como servicio, aprovechando todo el potencial de la nube.
El proceso puede requerir tiempo para determinadas cargas de trabajo, pero el impacto acumulado habilita un aprovechamiento total del TCO de tu infraestructura con el correr de los años.
Inversión Inteligente, Futuro Asegurado
La elección de GCVE no es un compromiso con la tecnología de ayer, sino una decisión inteligente de migración. Te permite resolver la urgencia del presente mientras habilitás el futuro de la modernización, con la flexibilidad financiera que ofrecen los Flex CUDs.
Si te quedaste con ganas de indagar un poco más sobre hacia dónde podrías transicionar tus cargas de trabajo en GCP, te recomiendo este episodio de nuestros #InsanePodcasts, donde contamos distintos escenarios posibles:Google Cloud VMware Engine: Cómo evitar la fatiga tecnológica
¿Buscás una estrategia segura para evolucionar tu entorno VMware?
Desde Wetcom podemos acompañarte con un Cloud Assessment 100% bonificado para evaluar tu entorno VMware (o de otra nube) y diseñar una Hoja de Ruta hacia la modernización progresiva.
¿Migrando a GCVE? También te ayudamos con la cotización de licencias y nodos.