5 cosas que podemos aprender del apagón
Hace unas semanas vivimos un apagón que afectó a casi todos nuestros clientes en mayor o menor medida. Me gustaría en este post recorrer algunos de los puntos más notables de esas horas de incertidumbre.
De estos puntos hay buenos, malos y feos. Todos relacionados con los servicios de TI propios y de nuestros clientes, de la operatoria y de planes que deberían haber funcionado de otra forma.
Y hablo de propios porque dentro del incidente nosotros también vimos afectada parte de nuestra operación. Estas cosas que tenemos que aprender fueron identificadas durante la crisis y analizadas posteriormente.
Desde los primeros minutos nos pusimos en contacto con nuestros clientes, sin importar qué tipo de servicio hubiera contratado con nosotros. Queríamos identificar los siguientes puntos:
1- Si tenían servicios afectados.
2- Estado de la operación del negocio.
3- Cuál era el plan de acción, si tenían.
4- La criticidad para devolver el servicio durante un domingo.
Debido a que tenemos clientes en las más diversas verticales, algunos tenían que operar el domingo sí o sí, y otros podían esperar a la madrugada del lunes.
De estas comunicaciones con los clientes y de las respuestas que obtuvimos, creamos este listado.
Vamos a empezar por lo bueno, lo que creo que funcionó bien dentro de todo ese proceso de incertidumbre.
No estamos tan mal como parece
Este es uno de los puntos buenos que quiero destacar. A pesar de lo que uno puede pensar, fueron pocos los clientes nuestros que vieron afectados completamente sus servicios.
Al menos desde el punto de vista de los servicios primarios del centro de cómputos.
Léase energía eléctrica junto con todos sus derivados (UPS, generadores, etc.) y refrigeración.
En casi todos los casos, por uno u otro método, los servicios continuaron siendo entregados con una mínima interrupción.
Los planes e inversiones que se hicieron en los últimos años demostraron ser eficientes.
Las comunicaciones siguen en funcionamiento
Este es otro de los puntos buenos del que podemos aprender. Si bien fueron muchos los que tenían energía eléctrica en sus centros de cómputo, no tenían acceso a ellos por fallas en algún punto de las comunicaciones.
Algo que no falló del todo sino hasta unas cuantas horas dentro del apagón fueron los servicios de datos de celulares. Esto quiere decir que podemos aprovechar tecnologías modernas de comunicaciones como SDWAN y apalancarlas por medio de servicios de respaldo como líneas de celulares.
Está claro que no es para reemplazar los servicios de acceso remoto, sino para ofrecer una vía adicional.
Si los servicios de datos de celulares demostraron funcionar como lo hicieron, deberíamos considerar adoptarlos como backup.
Acceso a la información vital para la operación
Claramente este es uno de los puntos malos del que tenemos que aprender.
Tener la información almacenada en nuestros servicios web y no poder acceder a los mismos por falta de comunicaciones es algo que no se debe repetir.
Desde no contar con una copia en otro servicio online de ese documento con el procedimiento de la configuración de la VPN o, mucho más grave, el procedimiento de apagado del centro de cómputos.
Tuvimos un caso donde llegamos a minutos de tener que apagar todo el centro de cómputos y no había acceso al procedimiento de apagado ordenado.
Si tenemos la información publicada desde nuestro centro de cómputos, deberíamos contar con parte de esta información replicada en otro servicio que permita el acceso en caso de ser necesario.
Las decisiones se toman antes
Dentro de los puntos malos quiero hablar también de la falta de planificación para este tipo de escenarios. Si bien lo más común a analizar, y crear, es un plan de recuperación de desastres, diferentes escenarios tienen que ser planteados.
Dentro de la práctica de DRP siempre tenemos que analizar diferentes escenarios, como el de un apagón o un evento prolongado que impactará en el servicio.
Esos escenarios se plantean durante la etapa de creación del plan y ante cada uno de éstos, se definen las acciones a tomar. Hacer esto con tanta anticipación permite tomar decisiones mucho más acertadas.
Durante el apagón encontramos muchos casos donde no había definiciones realizadas ante los eventos y encontramos mucha improvisación.
Este evento debería disparar inmediatamente una revisión de tu plan de recuperación de desastres si existe, o de lo contario, la creación de uno.
Las pruebas son clave
Para el final, dejo el feo, el peor punto de todos los puntos a mi gusto.
Encontramos un caso, de los que tomamos contacto inicial, que al consultar el estado de sus servicios nos informó que las UPS habían soportado la carga y que en breve darían arranque al generador de forma manual.
Nos informó que tenían combustible suficiente para operar por horas una vez el generador entrara en régimen y que estaban sin dificultades.
El generador nunca arrancó, las baterías se agotaron y el resto... es historia.
En este caso había un plan de pruebas trimestral del generador.
Un plan que no se ejecutaba hacía dos años. Sí, dos años.
Con el diario del lunes es fácil escribir estas reflexiones.
Durante el incidente, en algunos casos, se vivieron momentos de crisis que se podrían haber evitado con planificación, con pruebas y con un plan de recuperación de desastres que ni siquiera se hubiera llegado a disparar por completo.
No hay que esperar a otro apagón para planificar y hacer las definiciones ahora, cuando estamos tranquilos.
No podemos esperar a chocar el auto para contratar el seguro.
De todo esto tenemos que aprender. De lo bueno, de lo malo y de lo feo.
¿Te interesa saber más sobre las buenas prácticas de DRP? Contactanos https://www.wetcom.com/page/contactus
La ruta con Flex CUDs en GCVE
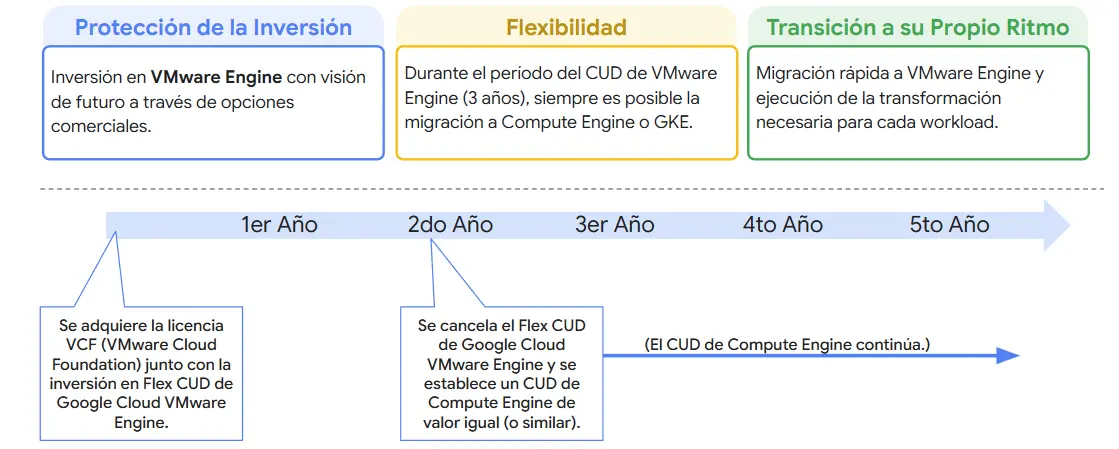
Siguiendo la captura anterior, tu inversión en los nodos de GCVE queda protegida durante todo el ciclo. Si en el segundo año decidís migrar una carga de VMware hacia Compute Engine (GCE) o GKE, podés cancelar el CUD de GCVE y transferir su valor remanente para establecer un nuevo CUD equivalente en GCE o GKE.
Esto te permite mantener el descuento, conservar el ahorro y acompañar la evolución de tus workloads, reflejando de manera precisa el enfoque de Lift, Run & Transform.
Conectividad Nativa: El Primer Paso hacia PaaS
Como mencioné antes, uno de los errores más comunes es ver GCVE como un silo. Su verdadero valor está en su conectividad nativa de baja latencia con el ecosistema de Google Cloud. Una vez que tu entorno VMware está en GCVE, tus aplicaciones heredadas están literalmente a milímetros de consumir servicios nativos de Google.
No aprovechar estos servicios nativos representa una pérdida del TCO real de la infraestructura. Por eso es fundamental utilizar el tiempo que GCVE ofrece para ser estratégicos con cada aplicación y planificar qué workloads pueden modernizarse sin disrupción.
Desde Wetcom hacemos especial foco en identificar el consumo base para dimensionar Flex CUDs con precisión, asegurando ahorro en todo el cómputo y habilitando una transición ordenada hacia otros servicios cuando tenga sentido.
Algunos ejemplos de caminos posibles y que podemos probar con PoCs sin disrupción incluyen:
- Hacia Google Compute Engine (GCE): Ideal para workloads que pueden beneficiarse de familias de máquinas especializadas, incluidas instancias con GPU o TPU.
- Hacia servicios PaaS de Bases de Datos: Como Cloud SQL, AlloyDB o Cloud Spanner. Muchas de estas transiciones se logran de manera transparente utilizando el servicio nativo Database Migration Service (DMS) para migraciones homogéneas. Esto libera la carga operativa de los DBAs delegando la responsabilidad a Google.
Un dato de valor, la posibilidad de probar bases de datos como las que mencione y sin disrupción es un gran beneficio, ya que al tener baja latencia entre GCVE y el servicio nativo, las pruebas de concepto no impactan el servicio de producción. - Hacia Contenedores (Cloud Run / GKE): GCVE facilita identificar qué VMs son candidatas naturales para avanzar hacia modelos cloud-native cuando llegue el momento.
Seguridad Nativa y Mitigación de Riesgos
Y no nos limitemos únicamente en la modernización de nuestras aplicaciones. La preocupación por la seguridad en la nube es natural, y en Google Cloud se aborda con un enfoque de “menor privilegio” y “guardrails” claros.
- La interconexión de GCVE con el VPC del cliente permite configurar micro-firewalls granulares, garantizando que solo los puertos y servicios estrictamente necesarios estén abiertos.
- Servicios como Cloud Armor, Next Generation Firewall (NGFW) y Security Command Center (SCC) ofrecen una batería de protección y análisis. SCC, en particular, analiza la infraestructura y alerta sobre riesgos, ofreciendo una guía de best practices para mitigar vulnerabilidades como ataques de ransomware.
- Y algo fundamental: establecer un Foundation adecuado desde el inicio, definiendo límites, permisos y controles por perfil de usuario, para evitar configuraciones riesgosas o costos inesperados. Desde Wetcom podemos acompañarlos en este diseño.
Pero mejor, veamos esta gráfica que resume claramente el recorrido que estamos describiendo:
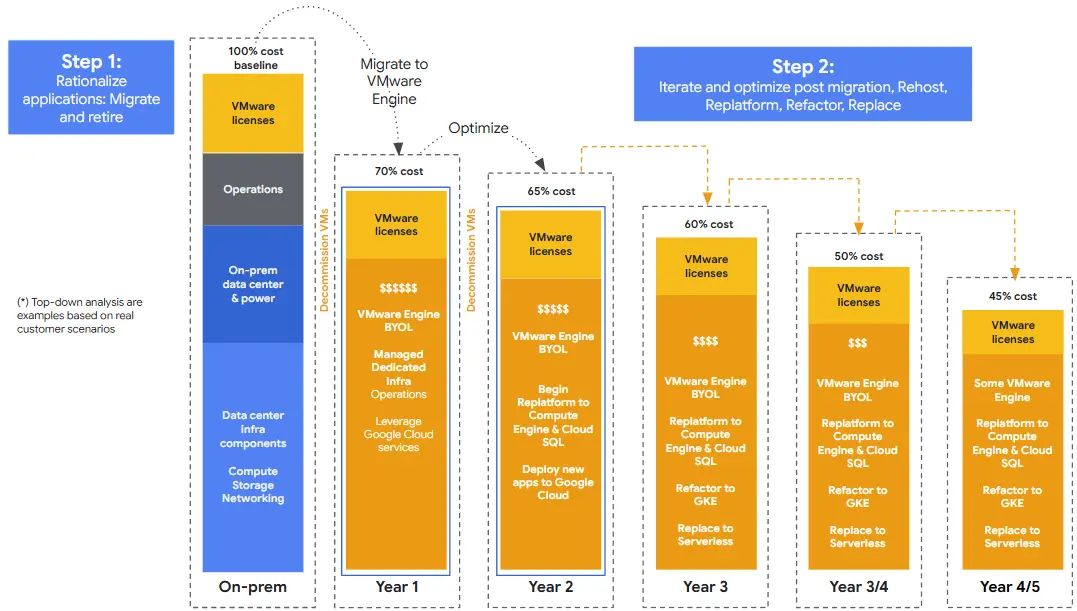
Esta gráfica de Google Cloud resume la hoja de ruta que podemos diseñar, mostrando cómo se pasa de un costo base del 100% on-premise a aproximadamente un 45% del costo original en el quinto año. Lo interesante es que este ahorro puede sostenerse —y amplificarse— gracias a los Flex CUDs, que permiten transicionar el compromiso a distintos servicios de cómputo a medida que avanzamos con el Replatform & Refactor hacia servicios como GCE o GKE. Esto habilita liberar nodos de GCVE y reducir, de forma progresiva, parte del licenciamiento de VMware que quedaría en desuso.
El resultado final es un entorno híbrido optimizado:
- GCVE para aquellas aplicaciones legacy que necesitan seguir ejecutándose allí, a milímetros de los servicios nativos de Google.
- Y el resto de las aplicaciones ya modernizadas sobre GCE, GKE o bases de datos como servicio, aprovechando todo el potencial de la nube.
El proceso puede requerir tiempo para determinadas cargas de trabajo, pero el impacto acumulado habilita un aprovechamiento total del TCO de tu infraestructura con el correr de los años.
Inversión Inteligente, Futuro Asegurado
La elección de GCVE no es un compromiso con la tecnología de ayer, sino una decisión inteligente de migración. Te permite resolver la urgencia del presente mientras habilitás el futuro de la modernización, con la flexibilidad financiera que ofrecen los Flex CUDs.
Si te quedaste con ganas de indagar un poco más sobre hacia dónde podrías transicionar tus cargas de trabajo en GCP, te recomiendo este episodio de nuestros #InsanePodcasts, donde contamos distintos escenarios posibles:Google Cloud VMware Engine: Cómo evitar la fatiga tecnológica
¿Buscás una estrategia segura para evolucionar tu entorno VMware?
Desde Wetcom podemos acompañarte con un Cloud Assessment 100% bonificado para evaluar tu entorno VMware (o de otra nube) y diseñar una Hoja de Ruta hacia la modernización progresiva.
¿Migrando a GCVE? También te ayudamos con la cotización de licencias y nodos.